Rich result eligibility is the set of conditions that gives a page a chance to appear with enhanced search presentation.
That chance is not a promise. A page can be eligible and still not show with a rich result. Eligibility means the page is built in a way that search systems can read, classify, and consider for richer presentation.
If you want the wider cluster first, start with the SERP Features hub. If you are working on the markup side, go next to JSON LD Basics, FAQ Schema, and HowTo Schema. If you are still deciding which result type a page should chase, read SERP Feature Prioritization and Best Format for the Query.
The short version
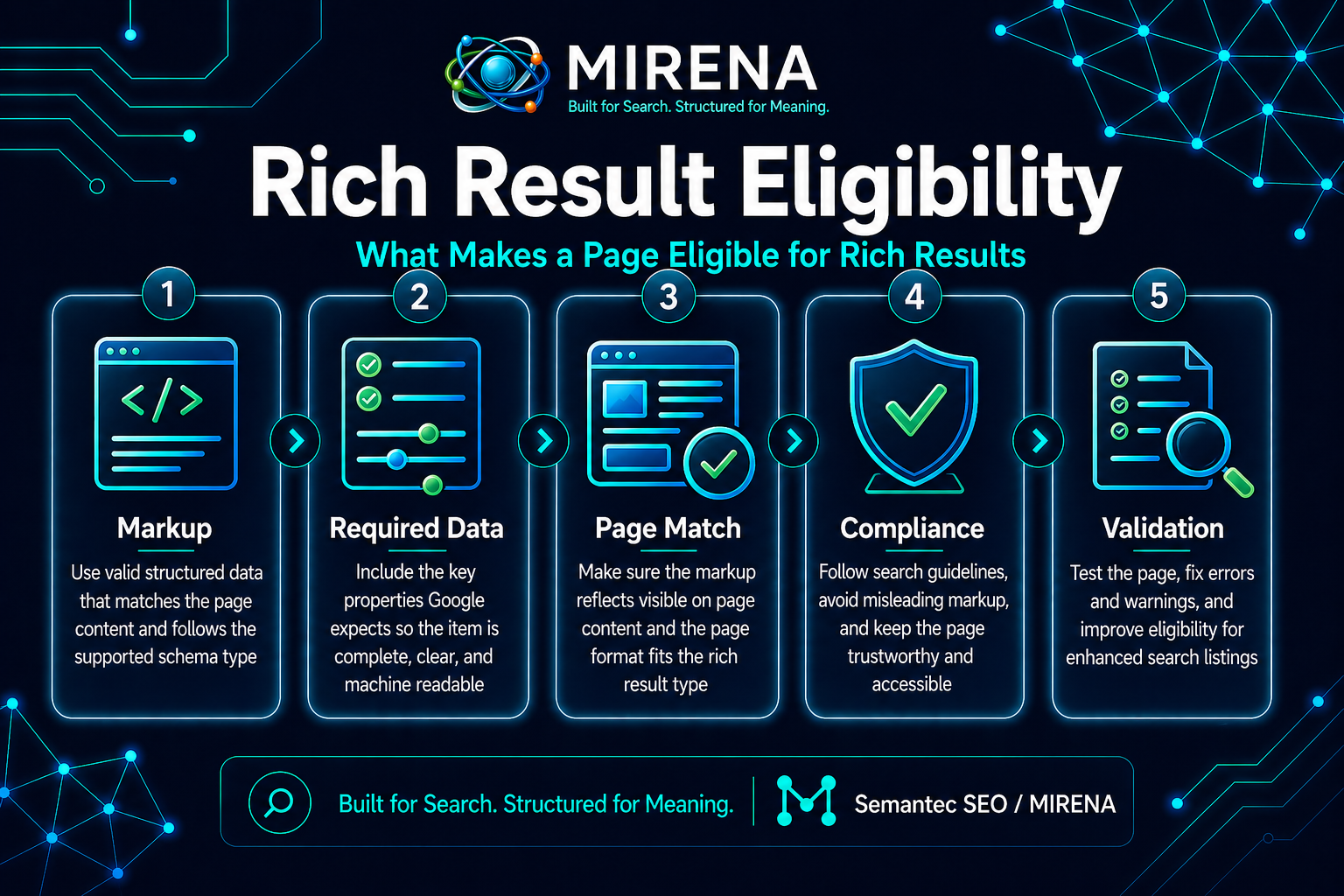
A page is more likely to be eligible for rich results when it has:
- the right page type for the result
- visible content that matches the markup
- valid structured data
- a clear page purpose
- clean technical access for crawling and indexing
If one of those breaks, eligibility gets weaker fast.
What rich result eligibility means
Rich result eligibility is not the same thing as ranking well.
It is also not the same thing as winning a featured snippet. Some result types rely heavily on page structure and retrieval shape. Others rely on structured data plus clear visible content. Rich result eligibility sits on the side of enhanced presentation.
A strong page can still miss that presentation if the markup is weak, the content does not support the markup clearly enough, or the page type does not fit the result pattern.
Rich results are not every search feature
This is a useful distinction.
A Featured Snippet can depend on answer shape and extraction. A rich result often depends on a tighter connection between page type, visible content, and structured data.
That is why this page sits between the SERP features cluster and the schema cluster. Rich result work is not just about formatting. It is also about page design, markup, and content clarity working together.
A page becomes eligible before it becomes competitive
A lot of teams jump straight to visibility and skip the first checkpoint.
The first checkpoint is simple:
Can this page qualify at all for the result type it is trying to support?
If the answer is no, no amount of copy polishing will fix that. The page has to fit the result type first. Then it can compete.
The five core parts of eligibility
1. The page has to fit the result type
A page cannot support every enhanced result style equally well.
A process page may fit a how to style result. A question page may fit FAQ style markup. A product page may fit product style markup. A business page may support organization or website level signals.
This is why format choice comes first. If the page role is unclear, eligibility gets weak before markup even enters the picture.
That is where Best Format for the Query helps. The page has to be the right kind of page before it can be the right kind of result candidate.
2. The visible content has to support the claim
Markup should reflect what the page clearly shows.
If a page uses schema for a question set, the questions and answers should be visible on the page. If a page uses product style markup, the product signals should be clear in the content. If a page supports a how to structure, the steps should be present in readable form.
This is one of the biggest failure points in rich result work. Teams add markup, but the visible page does not back it up well enough.
3. The structured data has to be valid
Even a well planned page can lose eligibility if the structured data is broken, incomplete, or placed in the wrong context.
That is why a page in this cluster should connect straight into JSON LD Basics and the specific markup pages that match the page type, such as FAQ Schema or HowTo Schema.
Markup is not the whole job, but broken markup can stop the job cold.
4. The page has to be easy to crawl and index
A page can have clean content and clean markup and still fail the first gate if it is not easy to access.
That includes basic indexability, crawl access, and page health. Rich result work sits on top of those basics, not in place of them.
5. The page purpose has to stay consistent
A page built for one job should not drift into three different jobs at once.
When the page tries to define, compare, answer side questions, and push a long process all in the same opening structure, it becomes harder for search systems to classify. Eligibility often gets cleaner when the page becomes narrower and more direct.
What supports eligibility most
A strong eligibility setup often comes from a short list of choices made early.
Clear page role
Know if the page is a product page, process page, question page, comparison page, or entity page.
Direct visible signals
Show the key content clearly on the page, not only in the code.
Matching markup
Use markup that fits the page and reflects what the reader can see.
Clean structure
Use headings, sections, lists, tables, and answer blocks that make the page easy to parse.
Stable internal context
Link the page into the right cluster so the wider site supports the page purpose.
If you are working on that last part, read Semantic Internal Linking and Anchor Text by Intent.
What blocks eligibility
A page can miss rich result eligibility for simple reasons.
Common blockers include:
- markup that does not match visible content
- missing required fields for the chosen schema type
- vague page purpose
- mixed page formats near the top
- thin or incomplete content for the claimed result type
- broken markup
- pages that are hard to crawl or index
- copied templates with no clear page level fit
This is why rich result work should not be treated as a plugin task. It starts in content planning.
Eligibility is not the same as display
This is one of the most useful things to keep clear.
A page can be eligible and still not appear with a rich result every time. Search presentation can change by query, result set, device, and competing pages.
So the right question is not:
Did we add markup?
The better question is:
Did we build a page that qualifies cleanly for this result type and supports that qualification with clear visible content?
A practical way to review eligibility
Use this five step review.
1. Name the target result type
Be specific.
Do not say “rich results” in the abstract. Say which result the page is trying to support.
2. Confirm the page role
Ask what this page is.
Product page, how to page, question page, docs page, organization page, founder page, or something else.
3. Check the visible content
Look at the page as a reader sees it.
Can a reader clearly see the content that supports the result type?
4. Check the markup against the page
The code should match the visible page, field by field and intent by intent.
5. Check the surrounding structure
Review headings, internal links, page context, and next step routing.
A page that looks isolated or mixed in purpose can weaken its own signal.
Rich result work starts in the brief
A lot of weak implementations happen because the brief never made the result target clear.
A good brief should define:
- the result type the page is trying to support
- the visible elements needed on the page
- the section order
- the markup type that fits the page
- the supporting internal links
- the checks to run before publish
That is why SERP Feature Briefing is a strong next step from here.
Rich result eligibility by page type
Question pages
Question pages need clear question and answer blocks, tight formatting, and markup that reflects what is on the page.
That is where FAQ Blocks fits into the workflow.
Process pages
Process pages need clear steps, a clean intro, and a readable sequence.
If you are working on that format, pair this page with How To Intros and Process Formatting.
Product and commercial pages
Commercial pages need tighter entity and offer signals, clearer visible details, and markup that reflects the page honestly.
Those pages also benefit from stronger product positioning through Knowledge Panel Support Content and Entity Markup.
Comparison pages
Comparison pages are often stronger when the visible comparison is already clear before markup is added.
That makes Comparison Tables and Table Design for Search useful support pages here.
Why teams miss the mark
The biggest mistake is treating rich result work like a code only task.
Other common mistakes include:
- choosing markup before choosing page role
- marking up content the page does not show clearly
- copying schema from another page without checking fit
- building broad pages that blur page purpose
- skipping validation and publish checks
A cleaner production model
A stronger workflow looks like this:
- choose the page role
- choose the target result type
- build the visible content for that result
- add markup that reflects the page
- validate before publish
- review performance after launch
That sequence keeps the page honest and keeps the markup aligned with the content.
How this connects to MIRENA style workflows
Rich result eligibility fits best when it is handled before the draft is finalized.
That means the brief should already know the page role, the feature target, the visible blocks required, and the schema path. If you want that planning layer, go next to MIRENA for Content Briefs. If the page is already live and needs repair work, the next step is often Snippet Loss Audit.
Final take
Rich result eligibility is the foundation layer behind enhanced search presentation.
A page becomes more eligible when the page type is clear, the visible content supports the claim, the markup is valid, and the wider page structure reinforces one clean purpose. A page becomes less eligible when the visible page and the markup drift apart.
If you want to build that path into the page plan, go next to SERP Feature Briefing. If you want the markup side, continue with JSON LD Basics and Entity Markup.
FAQ
What is rich result eligibility?
It is the set of conditions that gives a page a chance to appear with enhanced search presentation.
Does markup alone make a page eligible?
No. The page also needs visible content that matches the markup, a clear page role, and clean technical access.
Can an eligible page still miss rich results?
Yes. Eligibility gives the page a chance. It does not guarantee display.
What is the first thing to check?
Check the target result type and confirm that the page is the right kind of page for it.
What should I read after this page?
Start with SERP Feature Briefing, JSON LD Basics, and Snippet Loss Audit.