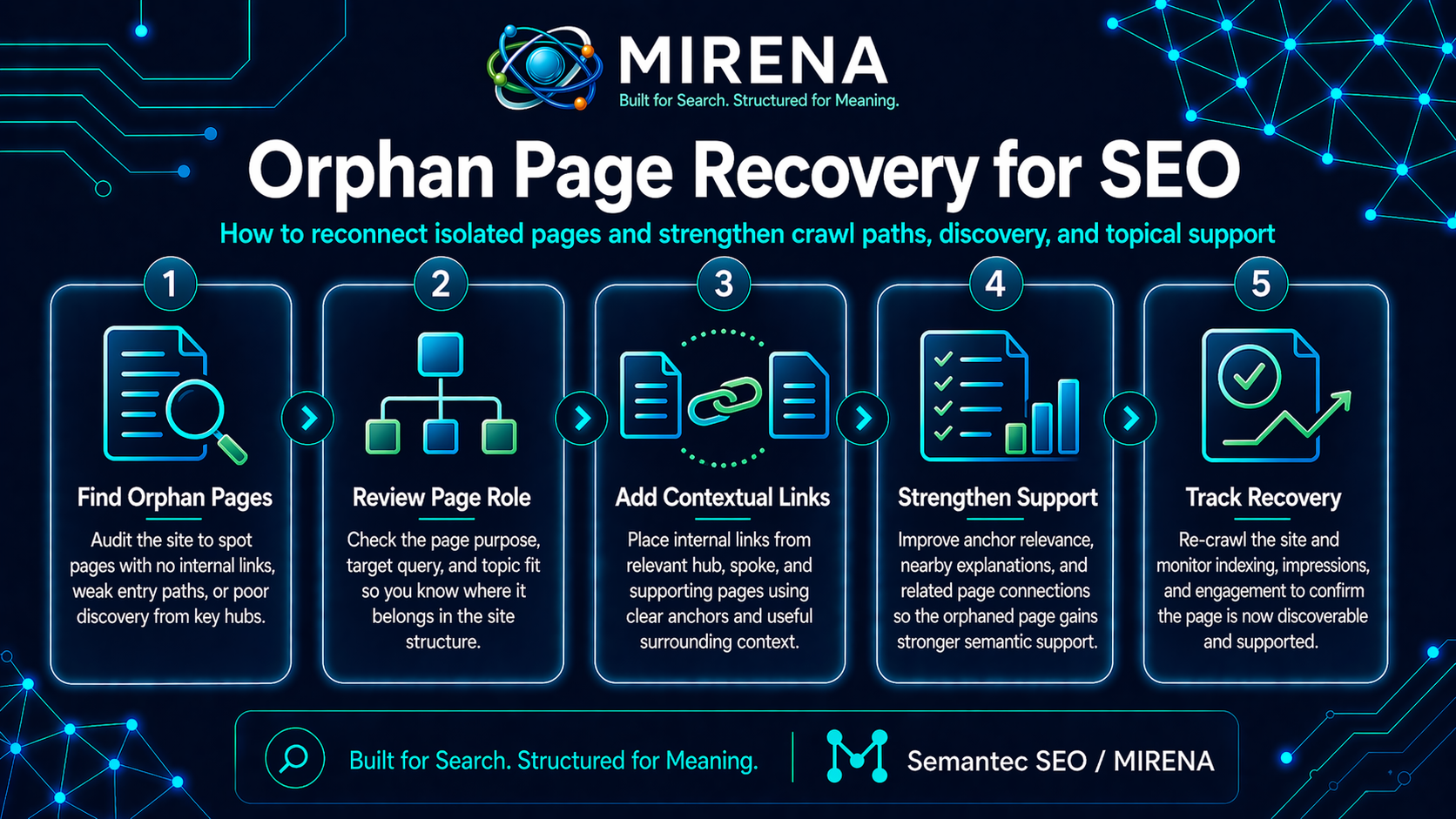
Orphan page recovery is the process of finding pages with no meaningful internal links, deciding which ones deserve a place in the site, and reconnecting them to the right hubs, support pages, and commercial paths.
This page belongs in the Internal Linking cluster because orphan pages are not just a crawl issue. They are often a site structure issue. A page can exist in the index and still sit outside the path readers and search engines use to move through the site. If you want the wider cluster view first, start with Semantic Internal Linking. If you want the review process behind the clean up work, go next to Internal Link Audit.
The short version
An orphan page is a page with no internal links pointing to it from the main site structure.
That creates two problems at once:
- the page is harder to discover and recrawl
- the page sits outside your topic paths, so it does less work for the rest of the site
Recovery is not just “add a link somewhere.” Good recovery means placing the page inside the right cluster, linking it from pages that make sense, and giving it a role that supports the broader site.
What counts as an orphan page
At the simplest level, an orphan page has no internal links from indexable pages on the site.
In practice, there are a few versions of the problem:
- a page has zero internal links
- a page has one weak link buried on an old page
- a page is linked only through XML sitemap discovery
- a page is linked from pages outside its topic path
- a page exists in the CMS but has no real place in the site structure
That last one is common on growing sites. Teams publish a draft, a landing page, a comparison page, or a refresh, but never connect it to the right hub.
Why orphan pages are a structural problem
Orphan pages do not just underperform on their own. They also break the logic of a cluster.
A clean site uses internal links to show relationships. Hubs support spokes. spokes support hubs. related pages connect across shared intent, shared entities, and shared next steps. When a page is orphaned, that relationship signal is missing.
That is why orphan page recovery belongs next to Semantic Internal Linking. Recovery is not only about getting a page recrawled. It is about placing the page inside the right semantic path.
How orphan pages happen
Most orphan pages come from one of five patterns.
1. Publishing outside the cluster plan
A page gets published before the hub, sibling pages, or link map are in place.
2. Site migrations and URL changes
A page survives the migration, but its internal routes do not.
3. Content refresh projects
A team republishes a page, changes its path, or merges copy, then loses the original linking pattern.
4. CMS and workflow gaps
A writer or editor ships a page without adding it to a parent page, template, nav block, or related page set.
5. Weak briefing
The brief covers the page topic but does not include link targets, parent hub, or cluster role. That is why Internal Link Briefing should sit upstream of publish work.
How to find orphan pages
The basic input is simple:
- crawlable URL inventory
- XML sitemap URLs
- known URLs from analytics, Search Console, or the CMS
- internal link data from a crawler
The recovery job starts when you compare the URL inventory against the internal link graph.
A page is a strong orphan candidate if it appears in one or more of these places:
- in the sitemap but not in the crawl path
- in analytics but not in cluster navigation
- in the CMS but not linked from any live page
- in Search Console but disconnected from the hub and sibling set
If you are doing this as part of a wider clean up pass, Internal Link Audit is the best companion page.
The recovery workflow
A solid orphan recovery pass has seven steps.
1. Build the orphan list
Start with a full URL list, then strip out pages that are blocked, redirected, canonicalized away, or meant to stay outside the crawl path.
What remains is the working set.
2. Split true orphans from weakly linked pages
Not every underlinked page is a true orphan.
Some pages are technically linked, but only through a weak or distant route. Those pages still need help, but the fix is different. A true orphan needs a first path into the site. A weak page needs a stronger path.
3. Assign each page a role
Before you add links, decide what the page is meant to be.
Is it:
- a hub
- a spoke
- a support page
- a bridge page
- a commercial page
- a proof page
- a utility page
This is where cluster thinking helps. A page with no role often becomes an orphan again.
4. Pick the best parent pages
A rescued page should not be linked from random spots. It should be linked from pages that make sense in the reader path and the topic path.
For most recoveries, that means linking from:
- the cluster hub
- one or two close sibling pages
- a page that introduces the same entity or subtopic
- a page that leads into the same next step
5. Write anchors that fit the page purpose
Anchor text should match the role of the destination page, not just repeat the same phrase every time. For anchor planning, use the logic behind Anchor Text by Intent.
A recovery link can use:
- exact topic anchors for clear definitions
- descriptive anchors for process pages
- comparison anchors for decision pages
- task based anchors for use case and workflow pages
6. Add at least one strong route into the cluster
A page is safer once it has more than one meaningful path from the site structure.
A common pattern is:
- hub to orphan page
- close sibling to orphan page
- orphan page back to hub
- orphan page to a next step page
That gives the page a place in both directions.
7. Recheck the cluster after the links go live
Once the links are live, rerun the crawl and review:
- internal link count
- depth from the hub
- route from sibling pages
- anchor variety
- crawl discovery
- traffic and engagement trend
Not every orphan page should be saved
Recovery is not the same as rescue at all costs.
Some orphan pages should be merged, redirected, rewritten, or dropped.
A page is a weak recovery candidate if it has:
- no clear cluster role
- no distinct query fit
- no useful link path into the site
- heavy overlap with a stronger page
- no next step for the reader
In those cases, the page may belong inside another URL or as a block inside an existing page.
Orphan page recovery at the cluster level
The biggest gains come when you stop treating orphan pages one by one and start looking at the cluster.
Ask:
- Which hubs are not supporting enough spokes?
- Which spokes have no sibling routes?
- Which pages sit outside the right topic lane?
- Which refresh pages were republished without being reconnected?
- Which use case or commercial pages are disconnected from support content?
That view turns orphan recovery into architecture work, not patch work.
A simple example
Picture a site with a live internal linking hub, an audit page, and a use case page, but a new orphan page on orphan recovery gets published without links.
That page may still be indexed, but it is floating.
A stronger version would connect it like this:
- the Internal Linking hub introduces orphan recovery as part of the cluster
- Internal Link Audit points to it when the audit finds disconnected URLs
- Semantic Internal Linking points to it when explaining relationship paths across the site
- the orphan recovery page points readers into MIRENA for Internal Linking when they want the workflow done inside the product
That is a linked system. The page no longer sits alone.
How to stop orphan pages from coming back
Recovery is only half the job. Prevention is the cleaner win.
Put link targets in the brief
A page brief should include:
- parent hub
- sibling pages
- supporting links to add
- next step page
- anchor direction
That is why Internal Link Briefing belongs upstream of publishing.
Make cluster role part of page approval
Before a page goes live, someone should be able to answer:
- What cluster owns this page?
- Which hub links to it?
- Which siblings support it?
- Which page does it route into next?
If those answers are missing, the page is not ready.
Recheck recovery candidates after refreshes and migrations
Many orphan pages appear after content operations, not during the first publish. Refreshes, URL moves, and template changes can break routes quietly.
Use a recurring audit cycle
A light recurring review catches pages that fall out of the structure after edits, removals, or site changes.
Orphan recovery and MIRENA
Inside MIRENA, orphan pages fit the site operator side of the workflow. The routing logic in your stack explicitly groups orphan pages with internal linking, cluster health, refresh audits, cannibalization, consolidation, and noindex review.
That means orphan recovery should not sit as a one off fix. It belongs in a repeated operating cycle:
- find disconnected pages
- assign or confirm page role
- place links from the right sources
- check anchor fit
- recheck crawl path
- review the next step route
Final take
Orphan page recovery is the work of giving disconnected pages a real place in the site.
The fix is not random links.
The fix is structure:
- the right hub
- the right siblings
- the right anchors
- the right next step
- the right page role
If a page cannot fit that system, it may need to be merged or removed. If it can fit the system, connect it with purpose and let it support the cluster.
If you want that work handled inside the product workflow, go to https://semantecseo.com/use-cases/internal-linking/.
FAQ
Are orphan pages always bad?
Not every disconnected page is harmful, but most orphaned pages do less work than they could. If a page has no place in the internal link structure, its value to the wider site drops fast.
Can a page rank with no internal links?
It can, but it is working with less support than a page placed inside a strong cluster.
Should every orphan page be recovered?
No. Some should be merged, redirected, or folded into stronger pages.
What is the first page I should read after this one?
Go to Internal Link Audit if you need the review process, or Semantic Internal Linking if you want the cluster logic behind recovery.